This article very much reflects my own thoughts on design systems, regardless of framework - React, Vue, whatever else.
I've worked on internal or B2B projects my whole career, and I'm usually working on something that can't be assembled entirely from third-party components - or at least not nicely. So when a design system is needed, I'm usually left underwhelmed by third-party options. I need something that makes it easier to build custom components, not something that does all the basics for me and then leaves me on my own to do the hard stuff.
The end result is a library where all the core stuff (colors, dark mode, spacing, fonts, etc.) and the simpler components (buttons, badges, pre-made grid layouts, etc.) are done from scratch, while the tricky stuff (dropdowns, charts, data grids) are the best well-supported open source libraries we can find. There's certainly more up-front work, but I've been thankful every time this approach was taken: with the system put together, building good custom components could not be easier.
The story of component-based web development: elements that might be simple at first can develop a surprising amount of complexity as time passes and features are planned.
Though the clever trick they do for the gradient background is clearly Facebook just showing off. I'd expect nothing less from a company worth over $100 billion.
If you know me, you know I love to talk about all the cool apps I've found to work with, but one of the most important kinds - and possibly the only kind that actually helps me be a better person? - are feed readers. I get a lot of useful stuff out of them:
Local and regional news for wherever I care about
The latest & greatest tricks & techniques for web development
Seeing when my city's website has an update about something important
Updates on the latest releases of apps I use & games I play
Tweets from accounts that I don't want to follow on my main timeline
New web comics as soon as they're published
You don't need RSS readers, also known as feed readers, to do any of these things. What they do for you is streamline the process, collecting all this stuff into a big bucket that you can go through whenever you want. Crucially, they allow you to read content much faster, enabling you to read in five minutes what you might not get to read even after a half hour of web-surfing.
None of that content comes out of the box, though: a feed reader is just a tool for fetching it. It's up to you to find & add the content you want to see.
What RSS Readers Are
Viewing starred articles in NetNewsWire
Many websites publish an updated feed every time they have a new article. These files are written to particular standards - RSS, Atom, or JSON Feed - and include article text, metadata like dates and authors, and other related information.
These feeds are then periodically downloaded by reader applications and services. You may have heard of Feedbin, Feedly, or NetNewsWire - these are all the same kind of application. (So was Google Reader, until Google shut it down.) When you use an RSS reader, you add feeds you find for sites across the web that you want to follow. Collect enough of these feeds, and you can explore a wealth of news and ideas every day - and you don't have to check the sites themselves to see if they're updated; the app will keep track of that for you. Laura Kalbag wrote an excellent guide to reading RSS if you want to dig into some more technical details.
The benefits are even greater for mobile devices. News sites tend to be particularly aggravating on mobile browsers, owing to heavy ad content and shaky design choices. Feed readers strip articles down to the bare copy and images, making them much faster to load and more consistently formatted. These are nice-to-haves on the PC, but quite important when you're on the go. This also comes with the nice little side-benefit that ads - unless in the form of "sponsored posts" - don't come along for the ride. Free ad-blocking!
You may have noticed that I said many websites update feeds... not most. Since Google Reader shut down, the prominence and popularity of RSS feeds has waned. To keep their readers up to date, many sites (particularly the bigger, corporate ones) have instead opted for email newsletters or posting links to Twitter, leaving most other RSS readers high and dry. This is why I want to focus on Feedbin, because this is one app that's not defeated so easily.
What Makes Feedbin Special
I don't want to turn this post into an advertisement for a paid feed service - not least because they're not paying me anything to write it! However, because Feedbin has features I can't bear to be without, they bear mentioning here too.
Feedbin, which costs $5 USD/mo for new users (a free trial is available), is the best RSS reader I've yet found. This is largely due to the well-built interface, but also to smart features that are either unique to Feedbin, or have an unusually good implementation.
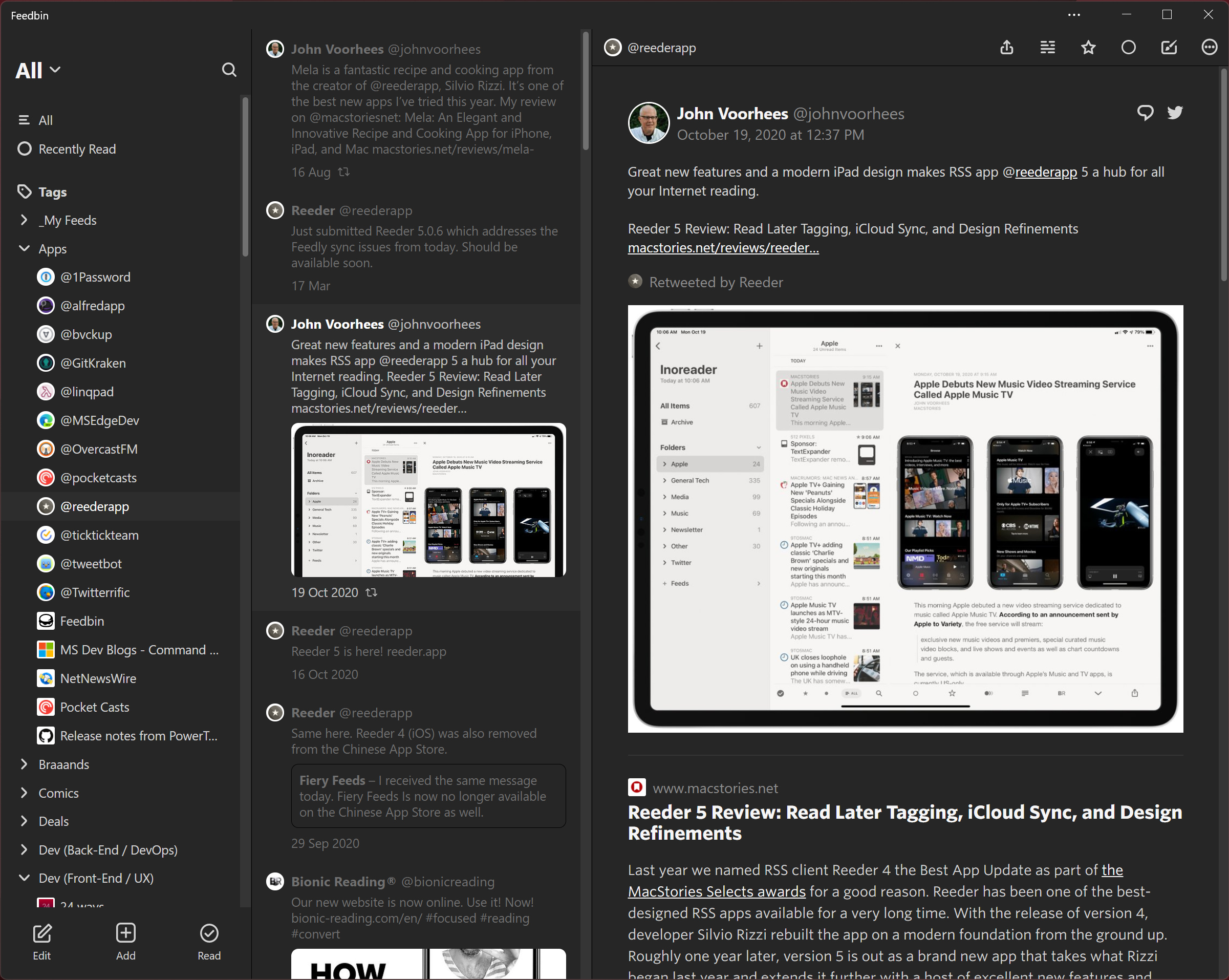
A review of Reeder, from a Twitter link, viewed in Feedbin
Possibly the most important difference Feedbin has from other RSS readers is that it's also a Twitter and newsletter reader. You can add Twitter usernames the same way you add a website's URL, and Feedbin will follow that account for you. Usually, it'll even load the text of posts that are linked to by those tweets. For newsletters, Feedbin provides an email address that you can use to subscribe to newsletters, and they'll show up in Feedbin instead of your email client.
Feedbin also has a very smooth "readability" mode. A dirty trick many sites do with their RSS feeds is include just a small snippet of content, forcing you to go to the site itself and generate ad revenue for them. On command, Feedbin will go fetch the webpage itself, attempt to extract the article from it, and display it in Feedbin. It's not perfect, as some sites go to silly lengths to prevent this, but it comes in handy. Feedbin's implementation is particularly good. Other apps with a "reading" mode might take many seconds to get that text, or force you to request it with every article. With Feedbin, it's fast and automatically done for every feed you tell it to do that for.
Feedbin's rules-based filters are also a powerful feature. Don't want to see any news featuring a certain troubling topic? You can mark every item with that topic in the title as already read, keeping them out of your unread items. If you want to get really crazy, you can filter out every article that doesn't have a term in the title or content. An example would be a state-wide news feed, where you only want to see stuff that happened in one particular town. A filter that looks for everything without that town's name in the title or content can hide everything else.
Another unique feature is that it can show the differences between the original and current version of an article, similar to "diff" tools used for comparing different versions of source code. Websites are a bit different from newspapers, in that past mistakes can be erased by the publisher right away. Feedbin tracks the original text and can tell you what got altered. This sometimes leads to some interesting revelations about leaked news, or how a provocative headline was watered down to reduce hate mail.
Other services, Feedly likely being the most popular, are available for free with paid pro versions. To me, the polished interface and extra features of Feedbin are well worth the extra expense. For the geeks out there, I should also mention that Feedbin is technically open source, so if you're feeling particularly brave you can try running your own copy of it.
Actually Using Feeds
I suspect the biggest reason why feed readers haven't really taken off is that finding RSS feeds isn't as easy as it should be. A site that's friendly to RSS readers (like mine!) will have links to feeds displayed in the footer or sidebar, while other sites, if they offer them at all, can really bury them. The good news is that sites are supposed to print links to them in the page source itself, so often you don't need to look at all. If a site has those links in the source, you can simply copy the URL into most RSS readers, and it will find the feed from that.
As it happens, websites with RSS feeds are not actually all that rare. I follow something like 130 feeds, newsletters, and Twitter accounts, many of them posting dozens of articles a day. That seems unmanageable, but that's the genius of an RSS reader. Because the posts are no longer heavy pages surrounded by ads from worldwide networks, the readers are much faster to use. You don't go to a site and browse its articles, but instead you look at the list, click every article, skim the title, and move on if it's not interesting. You're left reading all the articles you want, with no time wasted loading pages, and none that you don't.
It's no exaggeration to say that I can get through 30 posts a minute, assuming that only one or two in that bunch are too interesting to skip. That's the killer feature of RSS: you can cover so much more ground in a short amount of time than you could through old-fashioned web browsing. For staying informed, I find RSS readers to be an indispensable part of the process. Perhaps articles like this will help others discover the same!
Especially in the new world of component-based web development, color palettes help front-end and UX engineers keep things looking consistent, even compared to parts of the design they've never seen. The best way to create them should be to compute them from a few chosen source colors.
And yet, creating a useful, consistent, well-contrasted palette is deceptively difficult, because adjusting traditional RGB or even HSL values have little relation to the color's luminosity, or its contrast against another color. You end up doing a lot of hacks to tweak the colors to something more consistent or accessible, and eventually it turns into complex spaghetti code that makes you punch the keyboard when you find another issue. Despite attempts to do it the "right" way, I lived this reality twice at my last job, once again at my current one, and again with my blog. It's aggravating.
Next time, I'm taking a hard look at the guidance and new tooling offered in Eugene Fedorenko's post. It's much more than an admonition to stop using HSL, with great explanations of the problem and some solutions available for you to use. I'm sure it could save me a few headaches in the future.
This guide was very useful to me recently for a couple reasons. The first reason is pretty simple - I needed to build a switch component for work. Instead of trying to reinvent the wheel, I followed the guide (for the most part) and I think the results look pretty spiffy.
The more significant reason: I learned that there were a bunch of useful CSS properties that I haven't used before. It started out with familiar terms, but then I saw inline-size, block-size and outline-offset and my mind was blown a bit. I'd literally never heard of these, and I'm having to rethink how I build certain components moving forward. It also used the ::before selector, which I'm familiar with but haven't used a lot. Perhaps I should consider using it more extensively. The :indeterminate state was also new to me, and now that I'm aware, I feel like some authors are annoyed at how neglected it has been.
If you feel comfortable with CSS but don't consider yourself an expert, this article might just expand your horizons a bit.
I had never heard of Rach Smith until a week or so ago, yet her site is already one of my favorites. I'm pleasantly surprised at how relatable her thoughts and experiences are.
Having just fired up my blog again, her article Why write? seems particularly relevant at the moment, where she's laying down her reasoning towards investing time in her new site. This statement stuck out to me:
I don't want to look back on my life in 5 years and find the only things I have to show for my time are 5,000 changed nappies and 30,000 lines of code. I want a record of what I'm thinking and feeling.
From a public-facing point of view, that describes the last five years of my life pretty well. I'm hoping that my blog gives readers a sense of who I am, now and in the future.
As I get more involved with building UX tools for others to use, I want to have greater focus on the "why" behind a component, not just the superficial details. Runi Goswami, working with Lyft's Design Systems team, reflects on their thought process regarding a segmented control they developed, as they determined what contexts it belonged in and how to communicate that to the team. It's a process I hope to emulate with my own projects.
I am far from an artist, but I hope I get a chance someday to play around with this idea in my CSS work. SVG's can be aggravating, but I feel like the more I learn about them, the more impressed I am at the stuff you can pull off with them on the web.
Doug Wilson put together a list of stylish programming fonts. It's the first list I've seen that actually has monospaced fonts with some flair to them - not simply "hey, this one looks great at 10pt on an old screen, without aliasing" or "this one has ligatures for lambdas!"
Though my favorite monospaced font of all, Lotion, isn't on this list.
Much of my inspiration to do my handwriting font came from Jon Hicks' brilliant tribute to his late father. Needless to say, the motivations behind my font were very different, but it was great to see the process and techniques used to bring his dad's handwriting back for one more moment.